Info
24년 5월 말 작업 내용을 간단히 요약한 글입니다.
문제 상황
업무를 위해 Kibana에 접속했는데 특정 시점부터 로그 적재에 이상이 생긴 것을 확인했습니다.
문제 분석
GET /_cluster/health?level=shardsAPI 확인- Green이 정상 상태인데, 인지한 시점부터 정상 상태가 아님을 확인했습니다.
GET /_cat/shardsAPI 확인- 문제가 되는 인덱스의 샤드들이 노드에 할당되지 않은 것을 확인했습니다.
GET /_cluster/allocation/explain?prettyAPI 확인Elasticsearch isn't allowed to allocate this shard to any of the nodes in the cluster. Choose a node to which you expect this shard to be allocated, find this node in the node-by-node explanation, and address the reasons which prevent Elasticsearch from allocating this shard there. (...) the node is above the high watermark cluster…- 여기서 언급되는 High watermark는 Elasticsearch에서 서비스 장애 방지를 위해 작동시키는 디스크 할당 정책 3단계 중 하나인데, 자세한 사항은 다른 문서를 참고해 주세요.
- 핵심은, 디스크 용량이 부족해서 생긴 문제라는 것입니다.
GET /_cat/allocation?vAPI로 디스크 사용량도 확인했습니다.
일시적 해결 - 인덱스 삭제
- 해당 Elasticsearch에는 별도의 로그 삭제 정책이 없어 디스크가 가득 찼기 때문에 발생한 문제였고, 오래된 인덱스는 지워도 좋다는 확인을 받았습니다.
- 인덱스 몇 개를 삭제 후 샤드가 정상적으로 할당되고, 로그 적재도 정상화되었습니다.
- 인덱스 조회 :
GET /_cat/indices - 인덱스 삭제 :
DELETE /<index-name>
- 인덱스 조회 :
근본적 해결 - ILP 설정
일정 시간이 지나면 인덱스가 자동으로 삭제되도록 ILP(Index LifeCycle Policy)를 설정했습니다.
ILP 생성하기
Kibana에서 Stack Management → Index Lifecycle Policies 메뉴로 이동해 새 정책을 작성합니다.
Hot • Warm • Cold 3단계로 나누어져 있는데 여기서는 Hot phase만 사용할 것입니다. 더 복잡한 설정이 필요하다면 추가 검색을 추천드립니다.
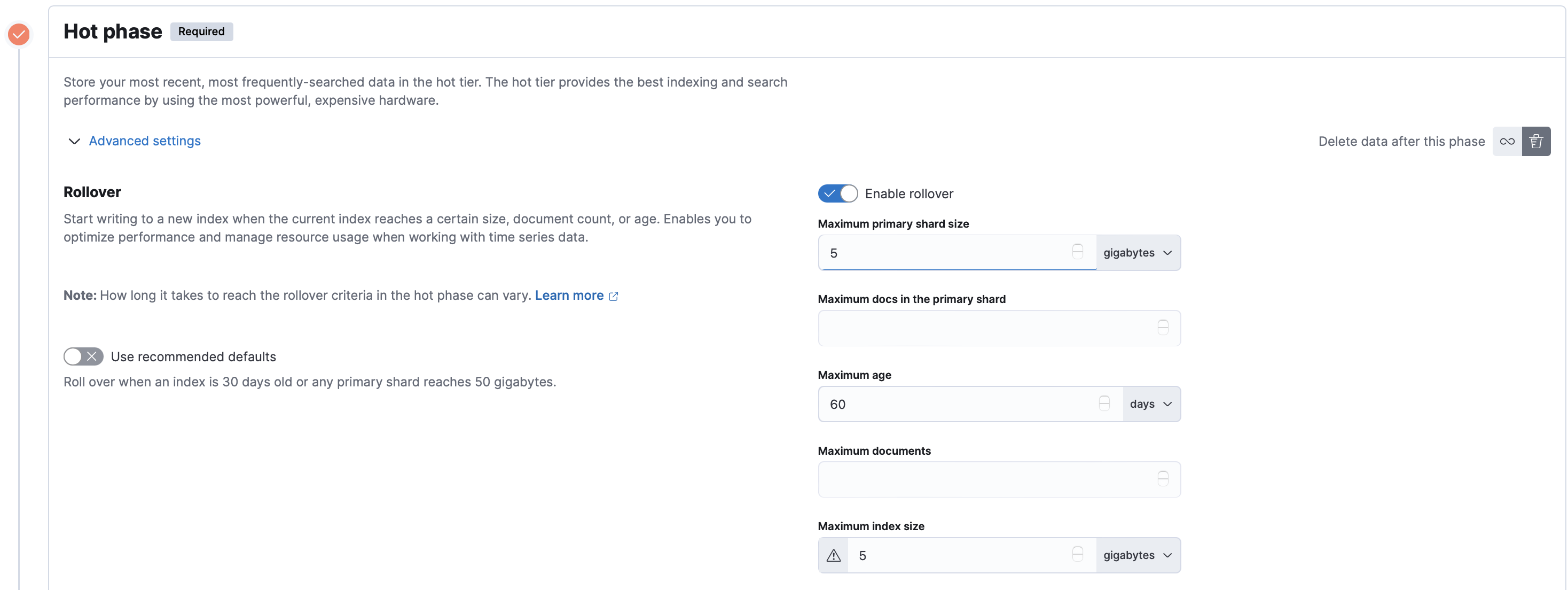
Hot phase
- Advanced settings에서 Use recommended defaults 옵션을 비활성화합니다.
- Delete data after this phase 옵션을 활성화합니다.
- 원하는 샤드 용량과 기간 제한을 설정합니다.
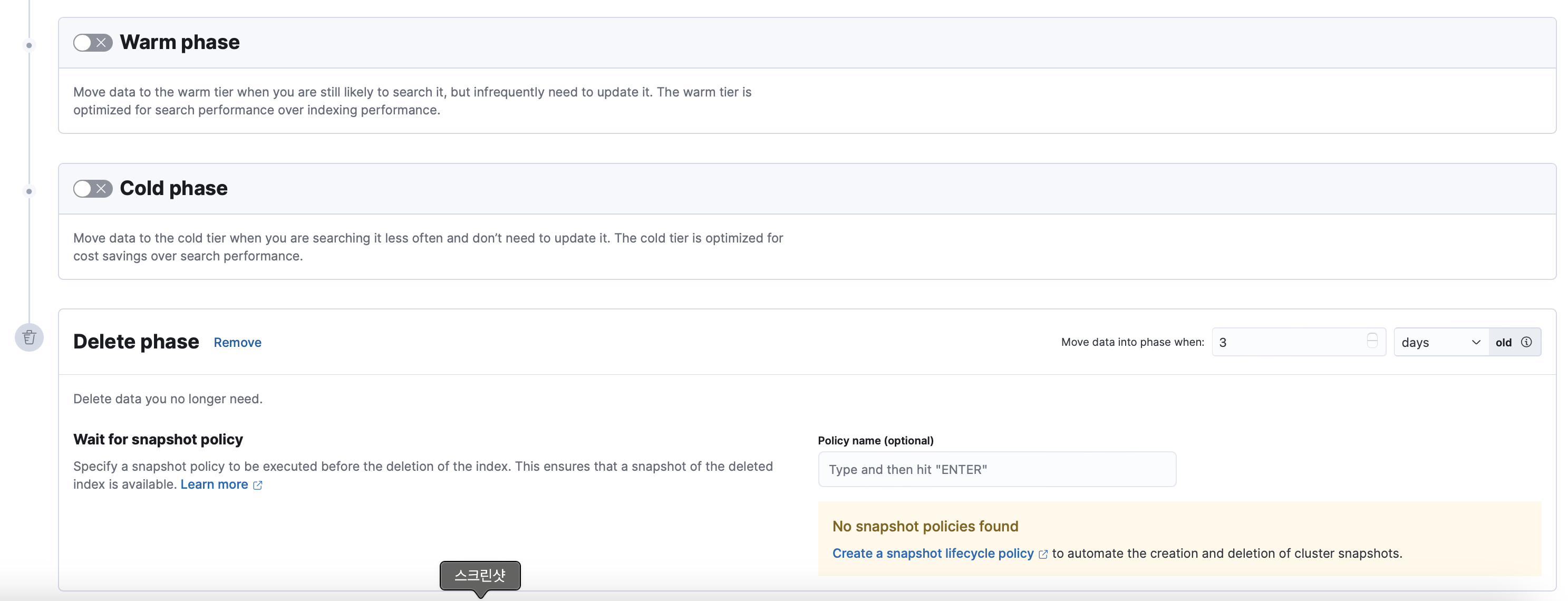
Delete phase
- 다른 것은 건드리지 않아도 되고, 얼마 동안 유지 후 삭제할지를 설정해 줍니다.
ILP 적용하기
Stack Management → Index Management → Index Templates 메뉴에서 Create template 버튼을 누릅니다.
다른 부분은 상황에 맞게 설정하거나 넘어가도 무방하고, 다음 2가지를 설정해야 합니다.
- Index patterns에서 원하는 인덱스 패턴을 설정합니다. 예)
your-pattern-* - Index settings에서 연결할 정책을 명시합니다.
{ "index": { "lifecycle": { "name": "<policy-name>" } } }
설정을 마치면 최종 확인 사항과 실행될 API 호출을 보여 줍니다.
PUT _index_template/<template-name>
{
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "<policy-name>"
}
}
}
},
"index_patterns": [ "your-pattern-*" ]
}생성 후 GET /_ilm/policy/<policy-name> API로 정책이 잘 적용되었는지 확인 가능합니다.